使用 perf_counter 處理券商 API 時間精度不足的問題
December 7, 2023
![]()
券商 API 回傳結果時間精度不足問題
對於多數券商 API 而言,無論你取得報價、回報等資料,券商 API 通常只會保證:
- 會依序拿到資料
- 必要的資料會包含時間(例如委託成功時間)
通常為了依序拿到資料,券商 API 會希望你盡快離開函數
例如報價可能是從 OnNewTick(tick) 這樣回來,你一開始將函數註冊給 API
一旦有新的 Tick 你的函數就會被調用:
def OnNewTick(tick):
print(f"新的 Tick: {tick}")
api.register("OnNewTick", OnNewTick)而只要你的 OnNewTick(tick) 還沒有處理完,通常就會阻塞到後續的 tick
甚至影響其他註冊函數的觸發(這將導致大量問題,未來持續探討)
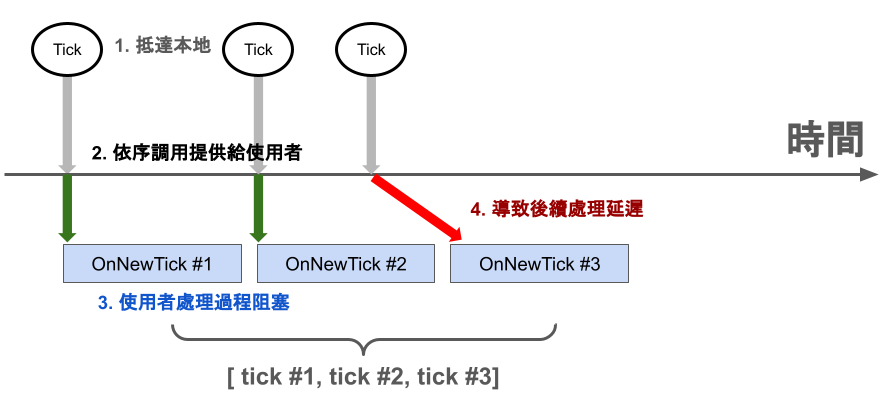
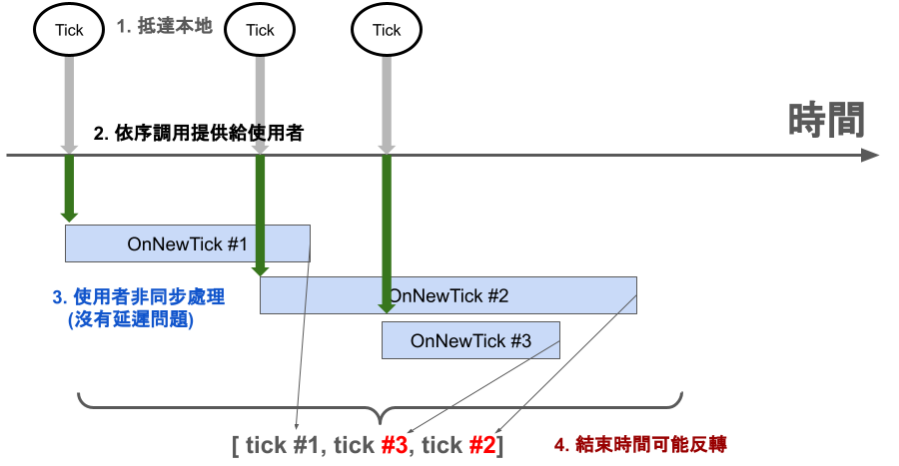
為了盡快地離開事件函數,通常就會用各種非同步、併發的方式處理
但是這就會導致每個事件觸發雖然在 API 給你的時候是依序的
但是為了不阻塞,你的非同步處理過程就可能導致結果亂序。
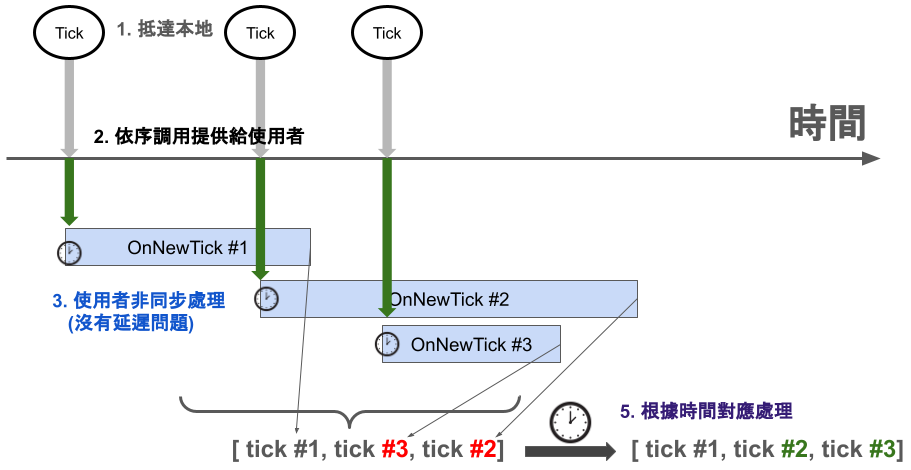
而資料本身的若有附帶時間,通常也不會足夠精細,例如只到毫秒等級
你可能會得到【一大批的資料,但是每一筆的毫秒時間是相同的】。
如果這時候你又非同步去處理,就需要特別紀錄時間(或是另一種方式,自己打流水號)
再根據流水號對應處理,例如等待、累積批次 … 等。
使用 time.perf_counter_ns()
就算再怎麼非同步,註冊函數被調用的順序是可以保證的
只要有順序,我們就能使用: time.perf_counter_ns() ,因為:
- 不受系統時間影響
- 單調遞增
- 精度到奈秒
, 但請注意,他不是時間,每次執行起始數值都不同:
import time
def OnNewTick(tick):
tid = time.perf_counter_ns()
print(f"(No.{tid}) 新的 Tick: {tick}")
# 假設 api 依序調用
OnNewTick({'bid': 611, 'ask': 766})
OnNewTick({'bid': 627, 'ask': 708})
OnNewTick({'bid': 646, 'ask': 781})
OnNewTick({'bid': 607, 'ask': 730})
OnNewTick({'bid': 653, 'ask': 770})
OnNewTick({'bid': 638, 'ask': 784})
OnNewTick({'bid': 603, 'ask': 760})
# (No.21820900) 新的 Tick: {'bid': 611, 'ask': 766}
# (No.21846100) 新的 Tick: {'bid': 627, 'ask': 708}
# (No.21850600) 新的 Tick: {'bid': 646, 'ask': 781}
# (No.21853900) 新的 Tick: {'bid': 607, 'ask': 730}
# (No.21857200) 新的 Tick: {'bid': 653, 'ask': 770}
# (No.21860200) 新的 Tick: {'bid': 638, 'ask': 784}
# (No.21863400) 新的 Tick: {'bid': 603, 'ask': 760}在絕大多數情況下, time.time() 是可以的,但是若:
- 遇到日光節約時間,或各種時間調整情況
- 或是程式在運行中物理移動導致系統時間自動校正
- 可能會導致
time.time()不保證遞增,並且沒有錯誤可以捕捉
所以可以考慮:
time.monotonic()time.perf_counter()
如果需要更精細的粒度,那就是用 perf_counter
又由於我們主要可能是用於比大小,正確依序處理券商資料
因此 int 可能更適合比較(浮點數是使用近似比较),那就用 perf_counter_ns
你可能會想要自己打流水號,但這就可能牽涉到跨子進程是否能安全共享流水號狀態
流水號遞增過程是否嚴格遞增。